오늘의 주제는 아래 페이지에 있습니다.
https://github.com/openai/openai-cookbook/blob/main/examples/How_to_stream_completions.ipynb
GitHub – openai/openai-cookbook: OpenAI API 사용을 위한 샘플 및 가이드

OpenAI API 사용을 위한 샘플 및 가이드. GitHub에서 계정을 만들어 openai/openai-cookbook 개발에 기여하세요.
github.com
완료를 스트리밍하는 방법
OpenAI Completions API를 호출하면 본질적으로 요청된 프롬프트를 완료한 다음 응답을 보냅니다.
다빈치 모델의 경우 매우 긴 완성을 만들면 답장까지 몇 초가 걸릴 수 있습니다. 2022년 8월 현재 text-davinci-002 모델의 응답 시간은 일반적으로 완료 토큰 100개당 1~2초입니다.
너무 오래 기다리지 않고 더 빨리 답변을 받고 싶다면 Stream을 사용할 수 있습니다.
이를 통해 요청된 프롬프트에 대한 응답을 완료하기 전에 응답의 일부를 가져와서 인쇄를 시작하거나 완료 시작을 처리할 수 있습니다.
완료를 스트리밍하려면 API를 호출할 때 stream=True를 사용하십시오. 이것은 텍스트를 반환하는 객체를 반환합니다. B. 서버에서 보낸 데이터 전용 이벤트. (즉, 응답의 일부라도 완료되면 응답을 스트림으로 계속 보낸다는 의미입니다.)
단점
한 가지 주의할 점은 프로덕션 애플리케이션에서 stream=True를 사용하면 완성 내용을 사용자 정의하기가 더 어렵다는 것입니다.
(즉, 스트리밍 시 응답의 일부만 저장되므로 전체 응답의 수정 또는 처리가 제한됨을 의미합니다.)
이 스트리밍 응답의 또 다른 작은 단점은 응답에 사용된 토큰 수에 대한 정보가 포함되어 있지 않다는 것입니다.
토큰 수를 알아내려면 모든 답변을 결합하고 토큰토큰을 사용하여 계산을 직접 수행해야 합니다.
샘플 코드
다음은 이러한 스트리밍 완성을 사용하는 Python 예제입니다.
# imports
import openai # for OpenAI API calls
import time # for measuring time savings첫 수입 openai. 그리고 응답 시간을 알아보기 위해 time 모듈도 가져옵니다.
# Example of an OpenAI Completion request
# https://beta.openai.com/docs/api-reference/completions/create
# record the time before the request is sent
start_time = time.time()
# send a Completion request to count to 100
response = openai.Completion.create(
model="text-davinci-002",
prompt="1,2,3,",
max_tokens=193,
temperature=0,
)
# calculate the time it took to receive the response
response_time = time.time() - start_time
# extract the text from the response
completion_text = response('choices')(0)('text')
# print the time delay and text received
print(f"Full response received {response_time:.2f} seconds after request")
print(f"Full text received: {completion_text}")이것은 스트림을 사용하지 않는 일반적인 방법입니다.
openai.Completion.create() 파라미터를 보면 stream=True 부분이 없습니다. 즉, 답을 얻기 위해 스트리밍을 사용하지 않습니다.
openai.COMpletion.create() API 호출 전 시간은 start_time에 포함되고 호출 후 시간은 response_time에 포함됩니다.
응답으로 받은 데이터에서 첫 번째 선택자의 텍스트 부분만 제거되어 complete_text에 저장됩니다.
그런 다음 총 경과 시간을 인쇄하고 두 번째 인쇄에서는 complete_text를 인쇄합니다.
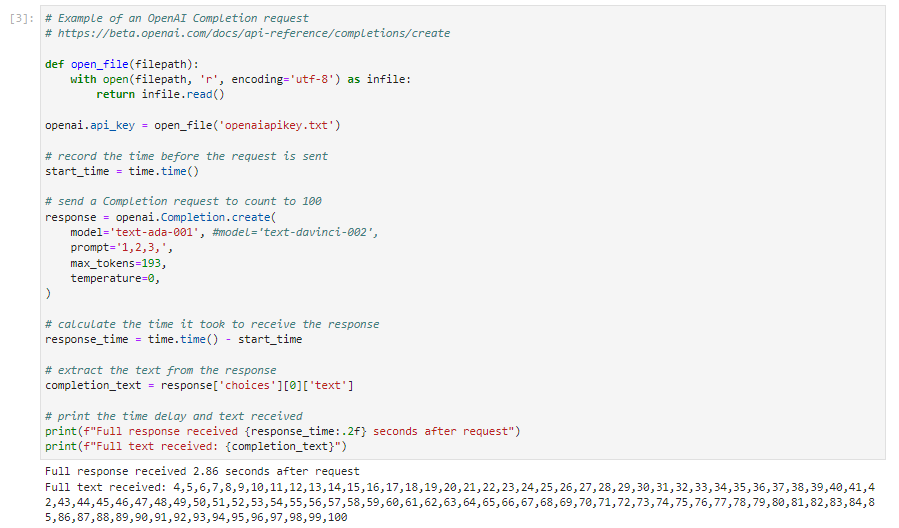
위의 소스 코드를 약간 수정했고, 텍스트 파일에서 openaiapikey를 읽어 인증을 받는 부분을 추가했고, 완성 API를 호출할 때 davinci보다 저렴한 ada 모델을 사용했습니다.
응답에는 2.86초가 걸렸으며 텍스트는 전체 텍스트로 수신됩니다.
스트리밍 완료 요청
# Example of an OpenAI Completion request, using the stream=True option
# https://beta.openai.com/docs/api-reference/completions/create
# record the time before the request is sent
start_time = time.time()
# send a Completion request to count to 100
response = openai.Completion.create(
model="text-ada-001", #model="text-davinci-002",
prompt="1,2,3,",
max_tokens=193,
temperature=0,
stream=True, # this time, we set stream=True
)
# create variables to collect the stream of events
collected_events = ()
completion_text=""
# iterate through the stream of events
for event in response:
event_time = time.time() - start_time # calculate the time delay of the event
collected_events.append(event) # save the event response
event_text = event('choices')(0)('text') # extract the text
completion_text += event_text # append the text
print(f"Text received: {event_text} ({event_time:.2f} seconds after request)") # print the delay and text
# print the time delay and text received
print(f"Full response received {event_time:.2f} seconds after request")
print(f"Full text received: {completion_text}")이번에는 스트리밍의 예입니다.
openai.Completion.create()의 매개변수를 보면 stream=True를 추가한 것을 볼 수 있습니다.
스트리밍 사용 방법.
그 이후의 코드는 이 스트리밍을 수신하는 방법을 인쇄하기 위해 작성된 스크립트입니다.
for 문이 있고 해당 for 문에서 응답에 있는 만큼의 이벤트가 실행됩니다.
이벤트가 발생할 때마다 이벤트 시간에서 start_time을 뺍니다. 즉, 이 계산은 클로저 API가 호출된 시점부터 이벤트가 발생할 때까지의 시간을 찾기 위해 수행됩니다. 해당 값은 event_time에 저장됩니다.
그리고 이 이벤트를 collect_events에 첨부합니다.
그리고 이 이벤트에서 받은 응답에서 첫 번째 선택 항목의 텍스트 콘텐츠를 가져옵니다.
complete_text에는 이전에 받은 evnet_text에 현재 받은 event_text가 추가됩니다.
그리고 for 문 안에 있는 print 문은 응답 내용과 응답을 받는 데 걸린 시간을 출력합니다.
for 문이 완료되면 총 경과 시간과 총 응답이 인쇄됩니다.
그러면 아래와 같은 응답을 받게 됩니다.
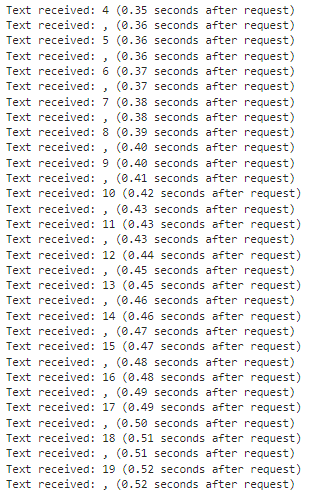
…….
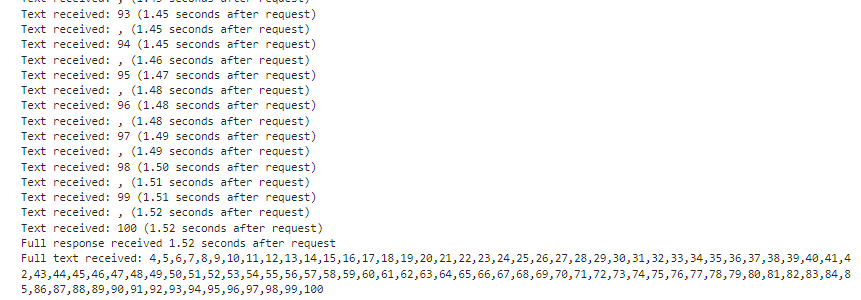
스트리밍 없이 전체 점수를 얻는 데 2.86초가 걸렸습니다.
그러나 이렇게 Stream을 사용하면 0.35초에서 응답 시작부터 전체 메시지를 수신하는 데 1.52초가 걸렸습니다.
스트리밍으로 얻은 모든 값의 합은 위에서 Stream을 사용하지 않은 것과 같습니다.
시간 비교
Davinci 모델을 사용하는 요리책 예제에서는 스트림 없이 7.32초, 스트림으로 7.25초가 걸렸습니다.
둘 다 거의 같은 시간이 걸렸지만 스트리밍을 사용하는 경우 응답의 일부 수신 시작에서 7.25초에서 전체 응답 수신까지 0.16초가 걸렸습니다.